금번 프로젝트에서 사용하는 검색엔진은 Elasticsearch 입니다. 2016년 무렵부터 Elasticsearch가 검색엔진 랭킹에서 1위를 차지할만큼 검색엔진 분야에서 지배적인 위치에 있기도 합니다. 이번 포스팅에서는 기본 개념과 특징에 대해서 알아보겠습니다.
What is Elasticsearch?
Elasticsearch vs RDB
개발자들이 흔히 아는 Relational Database와의 비교를 통해서 Elasticsearch의 개념을 조금 더 파악해보고자 합니다.
엘라스틱의 활용 사례가 늘어나면서 기존 DBMS를 엘라스틱으로 마이그레이션 하는 사례가 늘어나고 있습니다. 가장 큰 이유는 데이터의 저장 방식 때문입니다.
일반적으로 RDB는 행을 기반으로 데이터를 저장합니다. 그에 반해 엘라스틱서치는 단어를 기반으로(역인덱스, Inverted Index) 저장합니다. 이로 인한 장단점은 아래와 같습니다.
RDB는 데이터 수정·삭제의 편의성과 속도 면에서 강점이 있지만 다양한 조건의 데이터를 검색하고 집계하는 데에는 구조적인 한계가 있습니다. 예를 들어, RDMBS에서 ‘word’라는 단어가 db에 있는지 검색을 하려고 한다면 모든 row에 ‘word’라는 단어가 있는지를 검색하려고 하기에 비효율적입니다.
반면에 단어 기반으로 데이터를 저장하는 엘라스틱서치는 특정 단어가 어디에 저장되어 있는지 이미 알고 있어 모든 도큐먼트를 검색할 필요가 없습니다. row 기반 저장 구조와는 달리 단어가 저장된 row를 알고 있기 때문에 도큐먼트 개수와 상관없이 한 번의 조회로 검색을 끝낼 수 있습니다.
다만 이러한 특징 때문에 수정과 삭제는 엘라스틱서치 내부적으로 굉장히 많은 리소스가 소요되는 작업입니다. 이것이 엘라스틱서치가 RDBMS를 완전히 대체할 수 없는 중요한 이유 중 하나입니다. 따라서 데이터 특성상 수정과 삭제가 많은 경우와 그렇지 않은 경우를 잘 구분해서 어떤 검색 엔진을 사용할지 선택해야합니다.
용어 비교
다음은 Elasticsearch와 RDB의 용어를 비교한 표이다.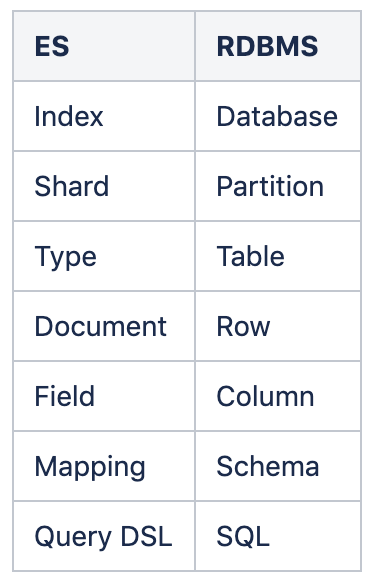
또한, ElasticSearch는 REST API를 사용하기에 용어들이 REST API와 유사합니다. 이를 관계형 데이터베이스와 비교하여 나타내면 아래과 같습니다.
Elasticsearch 문법
인덱스 입력, 조회 및 삭제 (GET, PUT, DELETE)
1. 인덱스 조회
GET 명령어를 활용하고 ip address와 index 이름을 아래와 같이 넣어준다.
1 | $ GET http://ip-address/index-name |
2. 인덱스 생성
PUT 명령어를 활용하고 ip address와 index 이름을 아래와 같이 넣어준다.
1 | $ PUT http://ip-address/index-name |
3. 인덱스 삭제
DELETE 명령어를 활용하고 ip address와 index 이름을 아래와 같이 넣어준다.
1 | $ DELETE http://ip-address/index-name |
데이터 조회 쿼리 만들기
엘라스틱 서치에서의 데이터 조회는 json 포맷으로 query를 만들어서 검색하는 Query DSL을 사용합니다.
match_all
match_all 쿼리는 지정된 index의 모든 데이터 즉, 특별한 검색어 없이 모든 document를 가져오고 싶을 때 사용합니다.
1 | { |
match
match 쿼리는 기본 필드 검색 쿼리로써, 텍스트/숫자/날짜를 허용합니다. 아래는 title이라는 필드에 keyword라는 용어가 있는 모든 document를 조회하는 예제입니다.
1 | { |
bool
bool 쿼리는 bool( true / false ) 로직을 사용하는 쿼리이며, 그 종류는 다음과 같습니다.
- must : bool must 절에 지정된 모든 쿼리가 일치하는 document를 조회
- should : bool should 절에 지정된 모든 쿼리 중 하나라도 일치하는 document를 조회
- must_not : bool must_not 절에 지정된 모든 쿼리가 모두 일치하지 않는 document를 조회
- filter : must와 같이 filter 절에 지정된 모든 쿼리가 일치하는 document를 조회하지만, Filter context에서 실행되기 때문에 score를 무시합니다.
아래는 나이가 40세이지만, Seoul 지역에 살고 있지 않은 document를 조회하는 예제입니다.
1 | { |
아래는 filter를 활용해서 날짜가 2021-10-20부터 2021-10-22일 사이의 document를 조회하는 쿼리입니다.
1 | { |