이전 포스팅에서는 도커에 대해서 알아보는 시간을 가졌습니다. 금번 프로젝트에서는 여러가지 다양한 딥러닝 모델을 하나의 gpu에서 사용하기 때문에, 자원의 효율적인 사용은 무엇보다 중요합니다. 따라서 사용하게된 Kubernetes의 개념에 대해 간단히 정리해보고자 합니다.
What is Kubernetes?
도커 vs 쿠버네티스?

도커를 간단하게 정의해서 이미지를 컨테이너에 띄우고 실행하는 기술 이라고 하면, 쿠버네티스는 도커를 관리하는 툴이라고 할 수 있습니다. 즉, 도커는 한 개의 컨테이너를 관리하는 데에 최적의 서비스라고 한다면, 쿠버네티스는 여러 개의 컨테이너를 서비스 단위로 관리하는 서비스입니다.
쿠버네티스를 쓰는 경우
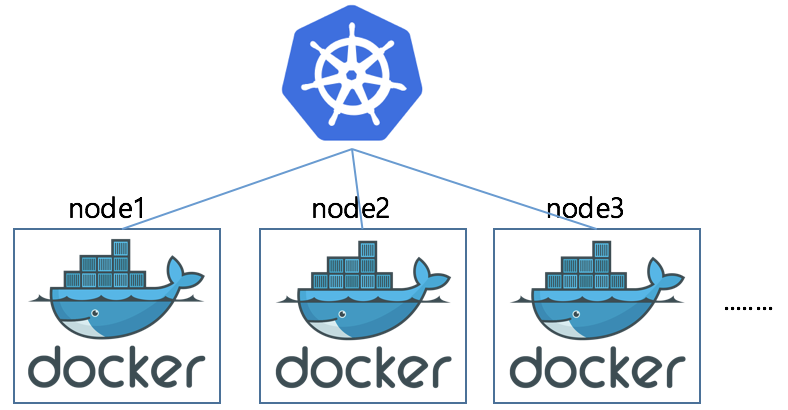
- 컨테이너의 수가 많아지면 관리와 운영에 어려움이 있습니다.
- 쿠버네티스는 이러한 다수의 컨테이너에 대한 실행, 관리 및 조율을 하는 시스템입니다.
- 쿠버네티스를 통해 컨테이너의 생성과 소멸, 시작 및 중단 시점 제어, 스케줄링, 로드 밸런싱, 클러스터링 등 컨테이너의 모든 과정을 관리할 수 있습니다.
쿠버네티스의 대표적 특징
자동 복구 시스템: 컨테이너를 모니터링하다가 컨테이너 중 하나라도 죽으면 쿠버네티스가 해당 컨테이너를 재시작 합니다.
노드 자동 밸런싱: 컨테이너에 노드가 많이 걸리면 새로운 컨테이너를 만들기도, 노드가 줄어들면 컨테이너의 숫자를 줄이기도 합니다.
결론
도커와 쿠버네티스는 상황마다 다르게 사용됩니다. 하나의 컨테이너만 사용하면 쿠버네티스는 필요 없겠지만, 많은 컨테이너 관리가 힘들다면 쿠버네티스가 유용합니다.