Deep Learning applications in Computer Vision
- 많은 분들이 아시다시피 아주 간단한 이미지 분류(Classification)부터, 이미지 생성(GAN)에 이르기까지, Vision과 관련되어 사용되는 딥러닝 기술들은 정말 다양합니다.
- 다양한 기술들이 있지만, Computer Vision에 사용되는 딥러닝 기술들을 크게 9가지로 나누고, 각 주제에 해당하는 대표적인 논문들을 한 편씩 돌아가면서 소개하고자 합니다. 🙂 이번 포스팅에서는 앞으로 살펴볼 각각의 기술들에 대해 간단히 살펴보도록 하겠습니다.
1. Image Classification
- 딥러닝을 공부하게 하면 배우는 Convolution Nueral Network(이하 CNN)가 대표적으로 적용되는 분야입니다. Classification이라는 단어 자체로 의미하듯, 0부터 9까지 숫자를 분류하는 MNIST dataset부터, 천가지 데이터를 분류하는 ImageNet까지 다양한 데이터 셋이 있습니다.

- 아래의 예시처럼, 각 이미지의 특징(feature)들을 얼마나 잘 구별해 내느냐가 딥러닝 모델의 성능을 좌우한다고 할 수 있겠습니다. 대표적인 논문으로는 AlexNet, ResNet, VGG 등이 있습니다.

2. Object Detection
- Classification 문제와 아래 사진과 같이 Bounding Box를 사용해서 그 물체의 위치 정보를 나타내는 Localization을 함께 할 수 있는 기술입니다.

- Object Detection 모델들은 크게 2-Stage Detecotr(R-CNN family)인지, 1-Stage Detector(YOLO or SSD family)인지를 기준으로 이해할 수 있습니다.
- Object가 있는 것으로 예상되는 위치에 대한 Regional Proposal을 받고, 그 다음 해당 영역이 어떤 Object인지 Classification을 수행하는 2단계로 모델이 작동한다면 2-Stage Detector이고, Regional Proposal과 Classfication이 동시에 계산된다면 1-Stage Detector라고 이해할 수 있습니다.
- 1-Stage Detector들은 실시간 처리에 빠른 성능을 보이지만 성능이 조금 2-Stage Detector들에 비해 떨어집니다. 예상하실 수 있겠지만 2-Stage Detector의 장점과 단점은 그 반대로, 속도는 조금 더 느리지만 Localization에 대한 상대적 정확도가 높다는 것입니다.
- 유명한 Dataset으로는 PASCAL VOC, Open Images 등이 있습니다.
3. Image Segmentation
- Segmentaion의 개념은 아래 사진으로 한 번에 이해하실 수 있을 것 같습니다. Detection을 하는 것에서 한 발더 나아가, Object의 경계까지 표시할 수 있는 기술입니다.
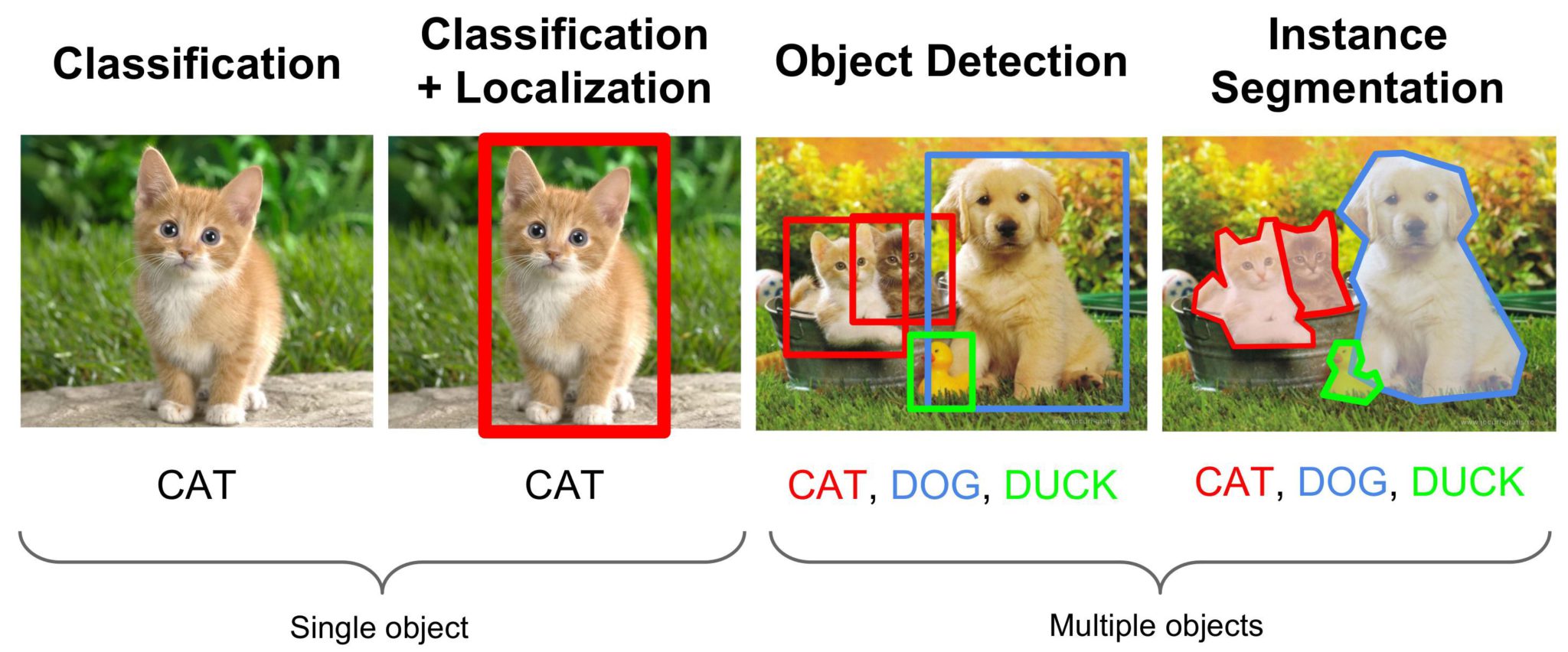
Semantic Segmentation과 Instance Segmentation의 차이점은 아래와 같습니다. 같은 이미지이 대해, 각자의 Object를 별개의 개체로 Segmentaion을 수행한다면 Instacne Segmentation이라고 지칭하며, Class만 구별하여 인식한다면 Semantic Segmentation이라고 지칭합니다.
유명한 모델로는 FCN, UNet, SegNet 등이 있고, 유명한 데이터셋으로는 COCO, PASCAL VOC 등이 있습니다.
4. Object Tracking
- Object Tracking은 Object Detection 기술을 응용, 발전시킨 좋은 예시입니다. Object Detection을 실시간으로 하면서, 맨 처음 Frame에서 Detection이 된 Object에게 ID를 부여하고, 다음 Frame에서는 해당 ID의 Object를 무엇으로 판별해야하는지에 대한 문제입니다.

- Object Tracking이 가능해지는 기본적인 원리는 다음과 같습니다.
Centroid based ID assignment
- Object Detection을 먼저 실시하고, Bouning Box마다 ID를 부여한다.
- 다음 frame의 bbox들 중, 현재 bbox의 중심점(centoids)과 가장 가까운 bbox 중심점을 가진 bbox에 현재 bbox의 ID를 부여한다.
- 위와 같은 경우, 두 사물이 겹치거나 Cross하며 지나가게 되는 경우에는 ID가 서로 바꿔치기가 될 가능성이 있습니다. 그래서, Kalman Filter 와 같은 방법을 사용하여, 각 bbox의 중심점이 어느 속도와 방향성을 가지고 움직이던 중이었는지를 기준으로 구별하여서 고유한 ID를 유지할 수 있게 해줍니다.
- 거기에 각각의 bbox가 가지고 있는 feature가 각 bbox안 이미지의 고유성을 더 설명해주는 식으로 ID의 Unique함을 더 유지할 수 있게 해준다면 더욱 Tracking이 잘 되겠죠?
- 유명한 논문으로는, SORT(Simple Online and Realtime Tracking), Deep SORT 등이 있고, Dataset으로는 MOT challenge dataset, Market 1501, MARS 등이 있습니다.
5. Pose Estimation
Pose Estimation은 Classification과 Localization의 또 다른 응용이라고 할 수 있겠습니다.
• Dataset마다 Pose를 구성하는 개수가 달라질 순 있지만, 아래와 같이 사람의 각 관절을 14군데로만 정한다고 했을 때, 해당하는 위치
[(x_1, y_1), (x2,y2) \sim (x{13}, y{13}), (x_{14},y_{14})]
들을 예측하고, 실제 값과 생기는 각각의 Regression Loss를 합하여 Back Propagation을 하는 방법으로 모델을 학습시킨다고 이해할 수 있습니다.

- 한 사진에 두 명이상이 있다고 했을 때에 모든 사람의 Pose를 파악을 해야하는 Multi-Pose estimation은 Single Pose Estimation보다 더 어려운 문제입니다.
- Multi-Pose 문제를 해결하는 방법으로는, 먼저 사람이라는 객체를 먼저 파악을 한 뒤에 각각의 사람에 대해 Pose Estimation을 수행하는 Top-Down approach와, 이미지 내 모든 사람들의 모든 관절들에 대해 먼저 예측을 실시하고 인접하거나 관련있는 포인트들끼리 grouping을 실시하는 Bottom-Up approach가 있습니다.
6. Image with GAN
- Generative Adversarial Network(이하 GAN)는 단어의 뜻을 하나씩 살펴보면 이해할 수 있습니다. 첫 번째 단어인 Generative. 즉, 생성한다는 말입니다. 아래의 사진은 실제로 존재하지 않는 사람들의 얼굴을 GAN을 사용해서 ‘만들어 낸’ 사람의 얼굴입니다.

• 이런 일이 어떻게 가능할까요? 쉽게 말하면, 이미지를 구성하는 픽셀들의 분포를 모델이 학습한다고 할 수 있습니다. 32×32 크기의 이미지가 있다고 했을때, RGB를 고려해, 총
[32\times32\times3=3162]
개의 픽셀이 어떻게 ‘분포’되어 조합이 됐길래 그러한 이미지를 생성할 수 있는지를 모델은 학습합니다. 그것이 가능하게 하는 아래와 같은 학습 방법을 ‘Adversarial’하다고 표현합니다.
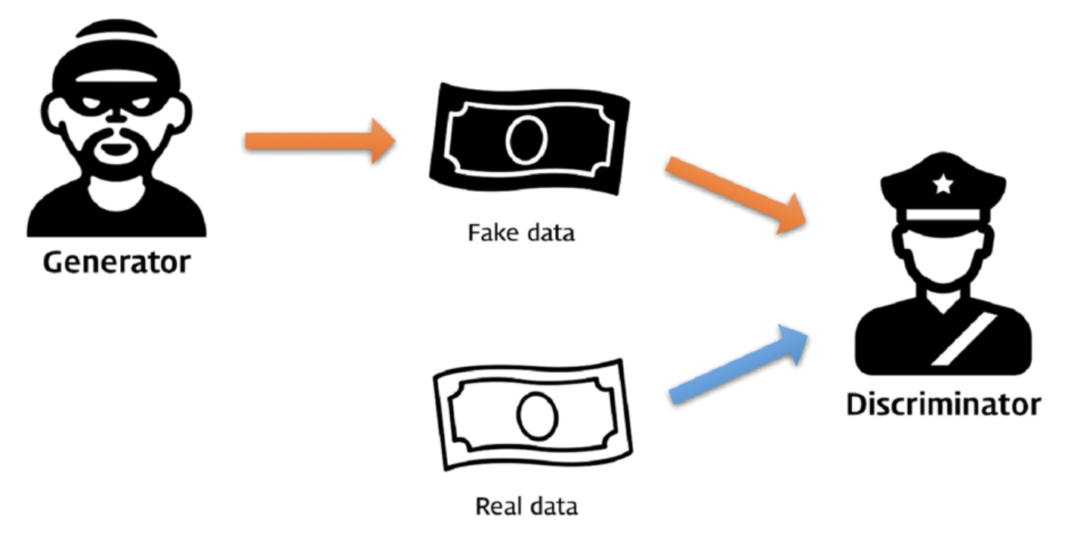
많이 들어보셨겠지만, GAN을 설명하는 가장 유명한 예시로 위조지폐범과 경찰을 듭니다. 위조지폐범은 실제 돈과 자신이 만든 위조지폐와 감별을 할 수 없을 정도로 정교하게 만들어야만이 구분자(Discriminator)인 경찰을 속일 수 있게 되는 것이고, 경찰은 반대로 생성자(Generator)인 도둑이 만든 위조지폐를 더 잘 구분하기 위해 또 학습을 하게 됩니다. 즉, GAN은 두 네트워크가 서로 대립적(Adversarial)하게 학습을 하는 형태를 가지고 있습니다.
유명한 모델로는 DCGAN, cGAN, WGAN, BEGAN, CycleGAN, DiscoGAN, StarGAN 등이 있고, 학습 데이터로는 fashionMNIST, Flickr-Faces-HQ Dataset (FFHQ) 등이 있습니다.
7. Image Captioning
- Image Captioning은 아래와 같이 사진을 보고 그 사진을 설명할 수 있는 기술을 뜻합니다.

CNN으로 이미지의 특징을 먼저 알아내고, 그 정보들을 RNN을 사용해서 서술하는. 어찌보면, 이미지 정보라는 언어를 사람의 언어로 통역을 시켜주는 기술이라고 볼 수 있겠습니다.
논문으로는 ‘Show and Tell’, ‘Show, attend and Tell’, ‘DenseCap’ 등이 있고, Dataset으로는 Visual Genome (VG) region captions, MS COCO, Flickr8k and Flickr30k 등이 있습니다.
위와 같이 Computer Vision과 관련된 논문들을 최대한 시간 순서대로 오래된 논문부터 차근차근 하나씩 꾸준히 리뷰해 나가도록 하겠습니다.