실제로는 종료 되었는데도 계속 남아있는 프로세스 Zombie process는 실제로는 종료된 프로세스이지만, Process Table에 여전히 남아있는 프로세스입니다. 이러한 Zombie process는 Defunct process라고도 부릅니다.
Zombie process가 생성되는 이유 일반적으로 프로세스는 부모 프로세스가 자식 프로세스를 실행하고, 자식 프로세스가 종료되어 부모 프로세스로부터 wait system call(e.g. waitpid)이 호출되면 Process table로부터 제거됩니다. 또한, 자식 프로세스의 실행이 종료된 이후에 부모 프로세스가 종료되면, 부모 프로세스와 함께 Process Table로부터 제거됩니다.
하지만 반대로, 부모 프로세스가 자식 프로세스보다 먼저 종료되는 경우 혹은 부모 프로세스가 자식 프로세스의 종료 처리 역할을 제대로 하지 못하는 경우 Zombie process가 생성됩니다.
Zombie process가 문제가 되는 이유 이렇게 Defunct process가 된 process는 같은 일부 시스템 리소스를 차지하게 됩니다. 그로인해 리소스의 용량이 꽉 차게 되면 더 이상 프로세스를 실행할 수 없는 상황이 발생할 수 있습니다.
딥러닝 프로젝트에서의 좀비프로세스 원인 금번 프로젝트에서는 pytorch 1.6을 사용하는 패키지를 사용했습니다. 그러나 프로젝트에서 사용하는 GPU서버가 pytorch 1.7이상 부터만 지원하기 때문에 문제가 발생했습니다. 이렇듯 딥러닝 프로젝트에서는 사용하려는 패키지와 실제 설치 되어있는 패키지 간 dependancy에 대해서도 정확히 고민해야합니다.
좀비 프로세스를 파악하는 방법
GPU 상에서 top 명령어를 통해 좀비 프로세스의 수, 좀비 프로세스를 확인할 수 있습니다.
금번 프로젝트에서 사용하는 검색엔진은 Elasticsearch 입니다. 2016년 무렵부터 Elasticsearch가 검색엔진 랭킹에서 1위를 차지할만큼 검색엔진 분야에서 지배적인 위치에 있기도 합니다. 이번 포스팅에서는 기본 개념과 특징에 대해서 알아보겠습니다.
What is Elasticsearch?
Elasticsearch vs RDB
개발자들이 흔히 아는 Relational Database와의 비교를 통해서 Elasticsearch의 개념을 조금 더 파악해보고자 합니다.
엘라스틱의 활용 사례가 늘어나면서 기존 DBMS를 엘라스틱으로 마이그레이션 하는 사례가 늘어나고 있습니다. 가장 큰 이유는 데이터의 저장 방식 때문입니다.
일반적으로 RDB는 행을 기반으로 데이터를 저장합니다. 그에 반해 엘라스틱서치는 단어를 기반으로(역인덱스, Inverted Index) 저장합니다. 이로 인한 장단점은 아래와 같습니다. RDB는 데이터 수정·삭제의 편의성과 속도 면에서 강점이 있지만 다양한 조건의 데이터를 검색하고 집계하는 데에는 구조적인 한계가 있습니다. 예를 들어, RDMBS에서 ‘word’라는 단어가 db에 있는지 검색을 하려고 한다면 모든 row에 ‘word’라는 단어가 있는지를 검색하려고 하기에 비효율적입니다.
반면에 단어 기반으로 데이터를 저장하는 엘라스틱서치는 특정 단어가 어디에 저장되어 있는지 이미 알고 있어 모든 도큐먼트를 검색할 필요가 없습니다. row 기반 저장 구조와는 달리 단어가 저장된 row를 알고 있기 때문에 도큐먼트 개수와 상관없이 한 번의 조회로 검색을 끝낼 수 있습니다.
다만 이러한 특징 때문에 수정과 삭제는 엘라스틱서치 내부적으로 굉장히 많은 리소스가 소요되는 작업입니다. 이것이 엘라스틱서치가 RDBMS를 완전히 대체할 수 없는 중요한 이유 중 하나입니다. 따라서 데이터 특성상 수정과 삭제가 많은 경우와 그렇지 않은 경우를 잘 구분해서 어떤 검색 엔진을 사용할지 선택해야합니다.
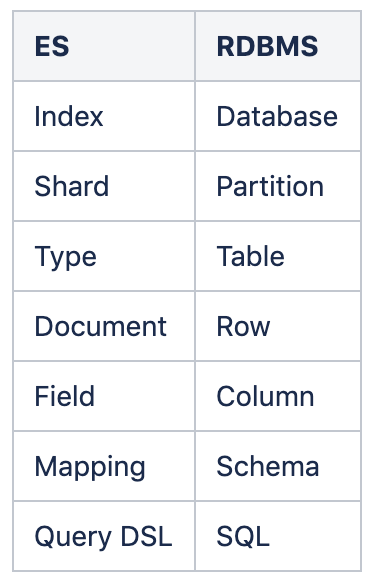
용어 비교
다음은 Elasticsearch와 RDB의 용어를 비교한 표이다.
또한, ElasticSearch는 REST API를 사용하기에 용어들이 REST API와 유사합니다. 이를 관계형 데이터베이스와 비교하여 나타내면 아래과 같습니다.
Elasticsearch 문법
인덱스 입력, 조회 및 삭제 (GET, PUT, DELETE)
1. 인덱스 조회 GET 명령어를 활용하고 ip address와 index 이름을 아래와 같이 넣어준다.
1
$ GET http://ip-address/index-name
2. 인덱스 생성 PUT 명령어를 활용하고 ip address와 index 이름을 아래와 같이 넣어준다.
1
$ PUT http://ip-address/index-name
3. 인덱스 삭제 DELETE 명령어를 활용하고 ip address와 index 이름을 아래와 같이 넣어준다.
1
$ DELETE http://ip-address/index-name
데이터 조회 쿼리 만들기
엘라스틱 서치에서의 데이터 조회는 json 포맷으로 query를 만들어서 검색하는 Query DSL을 사용합니다.
match_all match_all 쿼리는 지정된 index의 모든 데이터 즉, 특별한 검색어 없이 모든 document를 가져오고 싶을 때 사용합니다.
1 2 3 4 5
{ "query":{ "match_all":{} } }
match match 쿼리는 기본 필드 검색 쿼리로써, 텍스트/숫자/날짜를 허용합니다. 아래는 title이라는 필드에 keyword라는 용어가 있는 모든 document를 조회하는 예제입니다.
1 2 3 4 5 6 7 8
{
"query":{ "match":{ "title":"keyword" } } }
bool bool 쿼리는 bool( true / false ) 로직을 사용하는 쿼리이며, 그 종류는 다음과 같습니다.
must : bool must 절에 지정된 모든 쿼리가 일치하는 document를 조회
should : bool should 절에 지정된 모든 쿼리 중 하나라도 일치하는 document를 조회
must_not : bool must_not 절에 지정된 모든 쿼리가 모두 일치하지 않는 document를 조회
filter : must와 같이 filter 절에 지정된 모든 쿼리가 일치하는 document를 조회하지만, Filter context에서 실행되기 때문에 score를 무시합니다.
아래는 나이가 40세이지만, Seoul 지역에 살고 있지 않은 document를 조회하는 예제입니다.
제가 이번에 하게될 프로젝트에서는 자연어 처리 관련 딥러닝 모델을 활용하게 됩니다. 이러한 딥러닝 모델은 각각의 모델마다 사용해야하는 패키지, 서버 환경 등이 제각각이기 때문에 사용하는데 주의가 필요합니다. 딥러닝을 활용하여 서비스를 배포하기 위해서는 누구나 한번쯤 사용할법한 도커에 대해서 알아본 내용을 이번 포스팅에서 정리하고자 합니다. 우선 도커가 등장한 배경과 그리고 도커의 핵심 개념인 컨테이너와 이미지에 대해 알아보고 실제로 도커를 설치하고 컨테이너를 실행해 보도록 하겠습니다.
What is Docker?
도커란?
도커는 컨테이너 기반의 오픈소스 가상화 플랫폼입니다.
컨테이너라 하면 배에 실는 네모난 화물 수송용 박스를 생각할 수 있는데 각각의 컨테이너 안에는 옷, 신발, 전자제품, 술, 과일등 다양한 화물을 넣을 수 있고 규격화되어 컨테이너선이나 트레일러등 다양한 운송수단으로 쉽게 옮길 수 있습니다.
이처럼 도커에서 이야기하는 컨테이너도 다양한 프로그램, 실행환경 등을 컨테이너로 추상화하고 동일한 인터페이스를 제공하여 프로그램의 배포 및 관리를 단순하게 해줍니다. 매번 사용하는 패키지를 다시 깔거나 버전을 새로 맞추지 않아도 내가 짠 코드가 안정적으로 돌아갈 수 있도록 어디에서든 실행할 수 있습니다.
Docker for Mac / Docker for Windows 도커를 맥이나 윈도우즈에 설치하려면 Docker for mac 또는 Docker for windows를 설치하면 됩니다. 파일을 다운받고 설치하고 재부팅하면 대부분 문제없이 완료됩니다.
컨테이너(Container)
도커에서 가장 중요한 개념은 컨테이너와 함께 이미지라는 개념입니다.
이미지는 컨테이너 실행에 필요한 파일과 설정값등을 포함하고 있는 것으로 상태값을 가지지 않고 변하지 않습니다(Immutable). 컨테이너는 이미지를 실행한 상태라고 볼 수 있고 추가되거나 변하는 값은 컨테이너에 저장됩니다. 같은 이미지에서 여러개의 컨테이너를 생성할 수 있고 컨테이너의 상태가 바뀌거나 컨테이너가 삭제되더라도 이미지는 변하지 않고 그대로 남아있습니다.
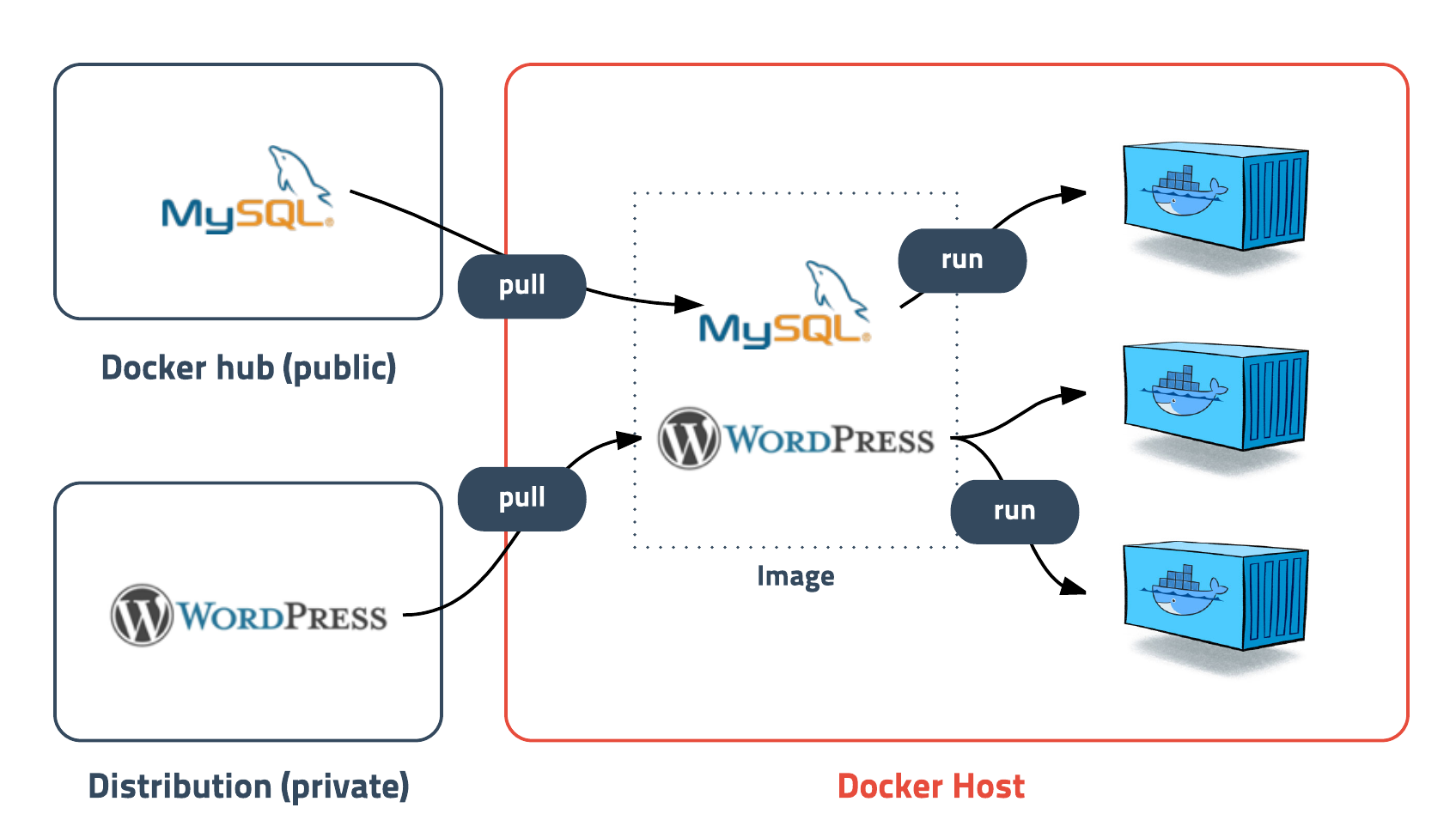
예를 들어 내가 필요한 패키지를 모두 설치한 이미지를 가지고 있으면, 코드나 설정값에 약간의 변화를 준 컨테이너를 여러개 만들 수 있습니다. Docker Image Hub에 가면 다양한 소프트웨어 업체 및 개인이 올려둔 도커 이미지를 확인할 수 있습니다. 유저는 자신만의 이미지를 생성하거나 도커허브에 올라와있는 이미지를 활용하여 컨테이너를 자유롭게 생성할 수 있습니다.
How to create a Docker image
도커는 이미지를 만들기 위해 Dockerfile이라는 파일에 자체 DSLDomain-specific language언어를 이용하여 이미지 생성 과정을 적습니다. 아래에 문법에 대해 자세히 다루겠지만 아래의 샘플을 보면 그렇게 복잡하지 않다는 걸 알 수 있습니다.
Dockerfile
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# Base Image FROM pytorch/pytorch:1.7.0-cuda11.0-cudnn8-runtime LABEL maintainer="shkim@saltlux.com"
ARG DEBIAN_FRONTEND=noninteractive
# Python 설치 RUN apt-get update && apt-get install -y wget\ python3-pip \ python3-dev \ postgresql-10 \ libpq-dev
COPY . /work
ADD ./requirements.txt ./requirements.txt RUN pip3 install --upgrade pip RUN pip install -r ./requirements.txt
위와 같은 dockerfile을 생성한 후 소스코드가 있는 폴더에 넣어둔 후 도커 이미지 생성을 진행하면 도커 이미지가 생성됩니다. 몇 가지 중요한 문법은 아래와 같습니다.
FROM : Docker hub에 있는 image 의 이름을 명시하면 됩니다. 자신이 구현하고자 하는 딥러닝 모델의 환경에 맞는 이미지를 찾아서 적습니다. 하나의 Docker 이미지는 base 이미지부터 시작해서 기존 이미지위에 새로운 이미지를 중첩해서 여러 단계의 이미지 층(layer)을 쌓아가며 만들어집니다.
FROM 명령문은 이 base 이미지를 지정해주기 위해서 사용되는데, 보통 Dockerfile 내에서 최상단에 위치합니다. base 이미지는 일반적으로 Docker Hub와 같은 Docker repository에 올려놓은 잘 알려진 공개 이미지인 경우가 많습니다.
RUN : RUN 명령문은 마치 쉘(shell)에서 커맨드를 실행하는 것 처럼 이미지 빌드 과정에서 필요한 커맨드를 실행하기 위해서 사용됩니다. 쉘(shell)을 통해 거의 못하는 작업이 없는 것 처럼 RUN 명령문으로 할 수 있는 작업은 무궁무진하지만 보통 이미지 안에 특정 소트트웨어를 설치하기 위해서 많이 사용됩니다.
CMD : CMD 명령문은 해당 이미지를 컨테이너로 띄울 때 디폴트로 실행할 커맨드나, ENTRYPOINT 명령문으로 지정된 커맨드에 디폴트로 넘길 파라미터를 지정할 때 사용합니다. CMD 명령문과 RUN 명령문이 햇갈릴 수가 있는데, RUN 명령문은 이미지 빌드 시 항상 실행되며, 한 Dockerfile에 여러 개의 RUN 명령문을 선언할 수 있습니다. 반면에, CMD 명령문은 이미지를 continaer로 띄울 때 딱 한 번 실행 기회를 가지게 됩니다.
EXPOSE : EXPOSE 명령문은 네트워크 상에서 컨테이너로 들어오는 트래픽(traffic)을 리스닝(listening)하는 포트와 프로토콜를 지정하기 위해서 사용됩니다. 호스트 컴퓨터로부터 해당 포트로의 접근을 허용하려면, docker run 커맨드를 -p 옵션을 통해 호스트 컴퓨터의 특정 포트를 포워딩(forwarding)시켜줘야 합니다.
COPY : COPY 명령문은 호스트 컴퓨터에 있는 디렉터리나 파일을 Docker 이미지의 파일 시스템으로 복사하기 위해서 사용됩니다. 도커 컨테이너 안에 소스파일을 밀어넣는 역할을 합니다.
How to deploy a Docker container
Docker build
이미지를 빌드하는 명령어 예시는 다음과 같습니다.
1
docker build -t image_name /path_to_image/
위와 같이 생성할 이미지 이름을 지정하기 위한 -t(–tag) 옵션만 알면 빌드가 가능합니다. 이미지가 잘 생성되었는지 확인하기 위해서는 아래와 같은 명령어를 사용할 수 있다.
1
docker images
output:
1 2
REPOSITORY TAG IMAGE ID CREATED SIZE image_name latest 54d239c00f11 4 minutes ago 209 MB
Docker run
Docker를 사용하면서 가장 자주 접하는 커맨드는 단연 컨테이너를 실행하기 위해서 쓰이는 docker run입니다. docker run 커맨드는 상당히 여러가지 옵션을 통해 다양한 방식으로 컨테이너를 실행할 수 있도록 해줍니다. 아래는 docker run을 사용하는 다양한 예제입니다.
-it 옵션 -i 옵션과 -t 옵션은 같이 쓰이는 경우가 매우 많은데요. 이 두 옵션은 컨테이너를 종료하지 않은체로, 터미널의 입력을 계속해서 컨테이너로 전달하기 위해서 사용합니다. 따라서, -it 옵션은 특히 컨테이너의 쉘(shell)이나 CLI 도구를 사용할 때 매우 유용하게 사용됩니다.
1 2 3 4 5 6 7
$ docker run -it python:3.8-alpine Python 3.8.2 (default, Mar 24 2020, 02:56:01) [GCC 9.2.0] on linux Type "help", "copyright", "credits" or "license"for more information. >>> print("Hi!") Hi! >>>
-d 옵션 많은 경우 컨테이너를 백그라운드에서 실행해야 하는데 이 때는 -d 옵션을 사용하면 됩니다. -d 옵션을 사용하면 컨테이너가 detached 모드에서 실행되며, 실행 결과로 컨테이너 ID만을 출력합니다. 예를 들어, python:3.8-alpine 이미지로 부터 python -m http.server 명령어를 백그라운드로 실행한 결과는 아래와 같습니다.
1 2 3 4 5
$ docker run -d python:3.8-alpine python -m http.server 0b920d2f561437418b8fdc0e9bcfdd4c9d634983ded18ba35a4dbae012753a72 $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 0e4fe552200f python:3.8-alpine "python -m http.serv…" 5 seconds ago
이 명령어를 -d 옵션없이 실행했다면, 해당 터미널에서 Ctrl + C를 눌러서 빠져나오는 순간 해당 컨테이너는 종료될 것입니다.
이렇듯 금번 프로젝트에서 사용한 도커에 대한 내용을 정리하였습니다. 다음 포스팅은 역시 이번 프로젝트에서 사용하게 된 쿠버네티스 환경에 대하여 살펴보도록 하겠습니다.
이전 포스팅에서는 도커에 대해서 알아보는 시간을 가졌습니다. 금번 프로젝트에서는 여러가지 다양한 딥러닝 모델을 하나의 gpu에서 사용하기 때문에, 자원의 효율적인 사용은 무엇보다 중요합니다. 따라서 사용하게된 Kubernetes의 개념에 대해 간단히 정리해보고자 합니다.
What is Kubernetes?
도커 vs 쿠버네티스?
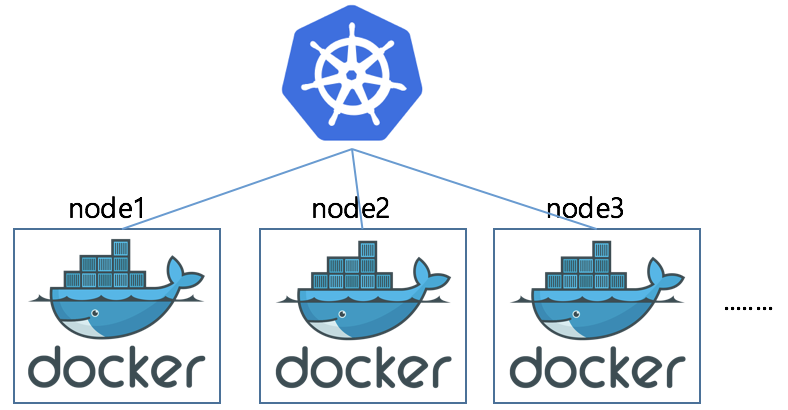
도커를 간단하게 정의해서 이미지를 컨테이너에 띄우고 실행하는 기술 이라고 하면, 쿠버네티스는 도커를 관리하는 툴이라고 할 수 있습니다. 즉, 도커는 한 개의 컨테이너를 관리하는 데에 최적의 서비스라고 한다면, 쿠버네티스는 여러 개의 컨테이너를 서비스 단위로 관리하는 서비스입니다.
쿠버네티스를 쓰는 경우
컨테이너의 수가 많아지면 관리와 운영에 어려움이 있습니다.
쿠버네티스는 이러한 다수의 컨테이너에 대한 실행, 관리 및 조율을 하는 시스템입니다.
쿠버네티스를 통해 컨테이너의 생성과 소멸, 시작 및 중단 시점 제어, 스케줄링, 로드 밸런싱, 클러스터링 등 컨테이너의 모든 과정을 관리할 수 있습니다.
쿠버네티스의 대표적 특징
자동 복구 시스템: 컨테이너를 모니터링하다가 컨테이너 중 하나라도 죽으면 쿠버네티스가 해당 컨테이너를 재시작 합니다.
노드 자동 밸런싱: 컨테이너에 노드가 많이 걸리면 새로운 컨테이너를 만들기도, 노드가 줄어들면 컨테이너의 숫자를 줄이기도 합니다.
결론
도커와 쿠버네티스는 상황마다 다르게 사용됩니다. 하나의 컨테이너만 사용하면 쿠버네티스는 필요 없겠지만, 많은 컨테이너 관리가 힘들다면 쿠버네티스가 유용합니다.
많은 분들이 아시다시피 아주 간단한 이미지 분류(Classification)부터, 이미지 생성(GAN)에 이르기까지, Vision과 관련되어 사용되는 딥러닝 기술들은 정말 다양합니다.
다양한 기술들이 있지만, Computer Vision에 사용되는 딥러닝 기술들을 크게 9가지로 나누고, 각 주제에 해당하는 대표적인 논문들을 한 편씩 돌아가면서 소개하고자 합니다. 🙂 이번 포스팅에서는 앞으로 살펴볼 각각의 기술들에 대해 간단히 살펴보도록 하겠습니다.
1. Image Classification
딥러닝을 공부하게 하면 배우는 Convolution Nueral Network(이하 CNN)가 대표적으로 적용되는 분야입니다. Classification이라는 단어 자체로 의미하듯, 0부터 9까지 숫자를 분류하는 MNIST dataset부터, 천가지 데이터를 분류하는 ImageNet까지 다양한 데이터 셋이 있습니다.
아래의 예시처럼, 각 이미지의 특징(feature)들을 얼마나 잘 구별해 내느냐가 딥러닝 모델의 성능을 좌우한다고 할 수 있겠습니다. 대표적인 논문으로는 AlexNet, ResNet, VGG 등이 있습니다.
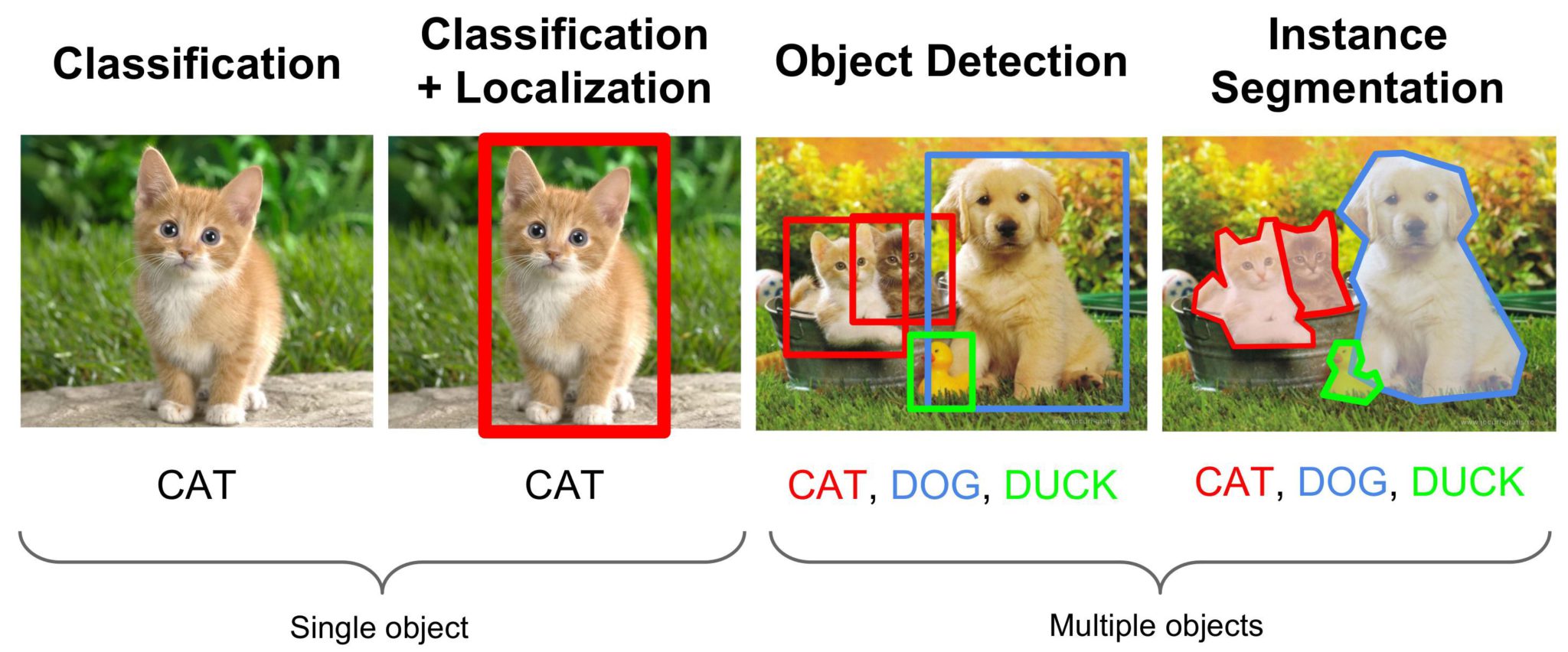
2. Object Detection
Classification 문제와 아래 사진과 같이 Bounding Box를 사용해서 그 물체의 위치 정보를 나타내는 Localization을 함께 할 수 있는 기술입니다.
Object Detection 모델들은 크게 2-Stage Detecotr(R-CNN family)인지, 1-Stage Detector(YOLO or SSD family)인지를 기준으로 이해할 수 있습니다.
Object가 있는 것으로 예상되는 위치에 대한 Regional Proposal을 받고, 그 다음 해당 영역이 어떤 Object인지 Classification을 수행하는 2단계로 모델이 작동한다면 2-Stage Detector이고, Regional Proposal과 Classfication이 동시에 계산된다면 1-Stage Detector라고 이해할 수 있습니다.
1-Stage Detector들은 실시간 처리에 빠른 성능을 보이지만 성능이 조금 2-Stage Detector들에 비해 떨어집니다. 예상하실 수 있겠지만 2-Stage Detector의 장점과 단점은 그 반대로, 속도는 조금 더 느리지만 Localization에 대한 상대적 정확도가 높다는 것입니다.
유명한 Dataset으로는 PASCAL VOC, Open Images 등이 있습니다.
3. Image Segmentation
Segmentaion의 개념은 아래 사진으로 한 번에 이해하실 수 있을 것 같습니다. Detection을 하는 것에서 한 발더 나아가, Object의 경계까지 표시할 수 있는 기술입니다.
Semantic Segmentation과 Instance Segmentation의 차이점은 아래와 같습니다. 같은 이미지이 대해, 각자의 Object를 별개의 개체로 Segmentaion을 수행한다면 Instacne Segmentation이라고 지칭하며, Class만 구별하여 인식한다면 Semantic Segmentation이라고 지칭합니다.
유명한 모델로는 FCN, UNet, SegNet 등이 있고, 유명한 데이터셋으로는 COCO, PASCAL VOC 등이 있습니다.
4. Object Tracking
Object Tracking은 Object Detection 기술을 응용, 발전시킨 좋은 예시입니다. Object Detection을 실시간으로 하면서, 맨 처음 Frame에서 Detection이 된 Object에게 ID를 부여하고, 다음 Frame에서는 해당 ID의 Object를 무엇으로 판별해야하는지에 대한 문제입니다.
Object Tracking이 가능해지는 기본적인 원리는 다음과 같습니다.
Centroid based ID assignment
Object Detection을 먼저 실시하고, Bouning Box마다 ID를 부여한다.
다음 frame의 bbox들 중, 현재 bbox의 중심점(centoids)과 가장 가까운 bbox 중심점을 가진 bbox에 현재 bbox의 ID를 부여한다.
위와 같은 경우, 두 사물이 겹치거나 Cross하며 지나가게 되는 경우에는 ID가 서로 바꿔치기가 될 가능성이 있습니다. 그래서, Kalman Filter 와 같은 방법을 사용하여, 각 bbox의 중심점이 어느 속도와 방향성을 가지고 움직이던 중이었는지를 기준으로 구별하여서 고유한 ID를 유지할 수 있게 해줍니다.
거기에 각각의 bbox가 가지고 있는 feature가 각 bbox안 이미지의 고유성을 더 설명해주는 식으로 ID의 Unique함을 더 유지할 수 있게 해준다면 더욱 Tracking이 잘 되겠죠?
유명한 논문으로는, SORT(Simple Online and Realtime Tracking), Deep SORT 등이 있고, Dataset으로는 MOT challenge dataset, Market 1501, MARS 등이 있습니다.
5. Pose Estimation
Pose Estimation은 Classification과 Localization의 또 다른 응용이라고 할 수 있겠습니다. • Dataset마다 Pose를 구성하는 개수가 달라질 순 있지만, 아래와 같이 사람의 각 관절을 14군데로만 정한다고 했을 때, 해당하는 위치 [(x_1, y_1), (x2,y2) \sim (x{13}, y{13}), (x_{14},y_{14})]
들을 예측하고, 실제 값과 생기는 각각의 Regression Loss를 합하여 Back Propagation을 하는 방법으로 모델을 학습시킨다고 이해할 수 있습니다.
한 사진에 두 명이상이 있다고 했을 때에 모든 사람의 Pose를 파악을 해야하는 Multi-Pose estimation은 Single Pose Estimation보다 더 어려운 문제입니다.
Multi-Pose 문제를 해결하는 방법으로는, 먼저 사람이라는 객체를 먼저 파악을 한 뒤에 각각의 사람에 대해 Pose Estimation을 수행하는 Top-Down approach와, 이미지 내 모든 사람들의 모든 관절들에 대해 먼저 예측을 실시하고 인접하거나 관련있는 포인트들끼리 grouping을 실시하는 Bottom-Up approach가 있습니다.
6. Image with GAN
Generative Adversarial Network(이하 GAN)는 단어의 뜻을 하나씩 살펴보면 이해할 수 있습니다. 첫 번째 단어인 Generative. 즉, 생성한다는 말입니다. 아래의 사진은 실제로 존재하지 않는 사람들의 얼굴을 GAN을 사용해서 ‘만들어 낸’ 사람의 얼굴입니다.
• 이런 일이 어떻게 가능할까요? 쉽게 말하면, 이미지를 구성하는 픽셀들의 분포를 모델이 학습한다고 할 수 있습니다. 32×32 크기의 이미지가 있다고 했을때, RGB를 고려해, 총 [32\times32\times3=3162]
개의 픽셀이 어떻게 ‘분포’되어 조합이 됐길래 그러한 이미지를 생성할 수 있는지를 모델은 학습합니다. 그것이 가능하게 하는 아래와 같은 학습 방법을 ‘Adversarial’하다고 표현합니다.
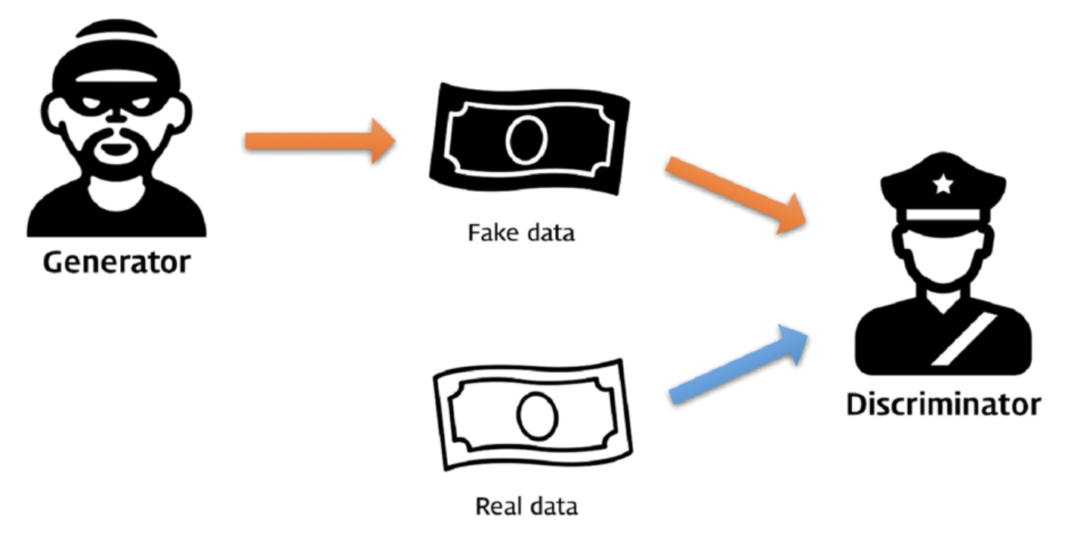
많이 들어보셨겠지만, GAN을 설명하는 가장 유명한 예시로 위조지폐범과 경찰을 듭니다. 위조지폐범은 실제 돈과 자신이 만든 위조지폐와 감별을 할 수 없을 정도로 정교하게 만들어야만이 구분자(Discriminator)인 경찰을 속일 수 있게 되는 것이고, 경찰은 반대로 생성자(Generator)인 도둑이 만든 위조지폐를 더 잘 구분하기 위해 또 학습을 하게 됩니다. 즉, GAN은 두 네트워크가 서로 대립적(Adversarial)하게 학습을 하는 형태를 가지고 있습니다.
유명한 모델로는 DCGAN, cGAN, WGAN, BEGAN, CycleGAN, DiscoGAN, StarGAN 등이 있고, 학습 데이터로는 fashionMNIST, Flickr-Faces-HQ Dataset (FFHQ) 등이 있습니다.
7. Image Captioning
Image Captioning은 아래와 같이 사진을 보고 그 사진을 설명할 수 있는 기술을 뜻합니다.
CNN으로 이미지의 특징을 먼저 알아내고, 그 정보들을 RNN을 사용해서 서술하는. 어찌보면, 이미지 정보라는 언어를 사람의 언어로 통역을 시켜주는 기술이라고 볼 수 있겠습니다.
논문으로는 ‘Show and Tell’, ‘Show, attend and Tell’, ‘DenseCap’ 등이 있고, Dataset으로는 Visual Genome (VG) region captions, MS COCO, Flickr8k and Flickr30k 등이 있습니다.
위와 같이 Computer Vision과 관련된 논문들을 최대한 시간 순서대로 오래된 논문부터 차근차근 하나씩 꾸준히 리뷰해 나가도록 하겠습니다.
When I realized it has been quite a long time since I decided to create my own blog, I thought I should not waste too much time to start off. Although there are various types of blog platforms that give you instant results, I thought it would be better to have a blog based on Github since I want to pursue my career as a developer. In today’s post, I will talk about which kinds of strengths a Hexo blog has, how to create your own Hexo blog and how to add a comment section to your blog.
나만의 블로그를 만들기로 결정한 지 꽤 오랜 시간이라는 걸 깨달았을 때 더 이상 너무 많은 시간을 낭비해서는 안된다고 생각했습니다. 즉각적인 결과를 얻을 수있는 다양한 유형의 블로그 플랫폼이 있지만 저는 개발자로서의 경력을 쌓고 싶기 때문에 Github를 기반으로 한 블로그가 더 좋을 것이라고 생각했습니다. 오늘의 글에서는 Hexo 블로그의 장점, 자신 만의 Hexo 블로그를 만드는 방법, 블로그에 댓글 섹션을 추가하는 방법에 대해 설명하겠습니다.